How does CSS work under the hood?
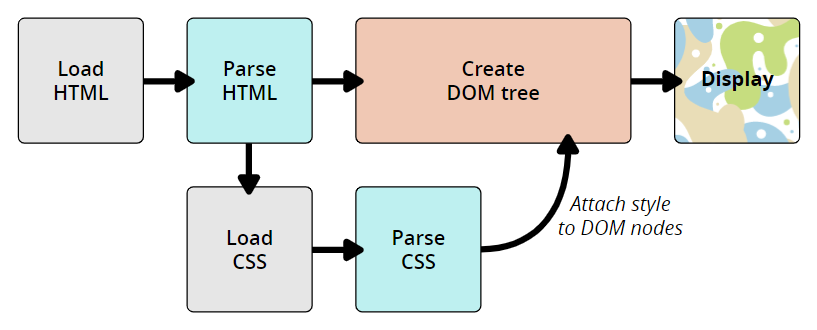
The CSS language is designed to be used alongside a "markup" language like HTML. CSS defines how HTML elements are formatted – controlling their layout, colors, fonts, and so on. When a browser displays a document, it must combine the document's content with its style information. It processes the document in a number of stages, which we've listed below.
- The browser loads the HTML (e.g. receives it from the network).
- It converts the HTML into a DOM (Document Object Model).
- The browser then fetches most of the resources that are linked to by the HTML document, such as embedded images and videos and linked CSS.
- The browser parses the fetched CSS, and sorts the different rules by their selector types into different "buckets", e.g. element, class, ID, and so on. Based on the selectors it finds, it works out which rules should be applied to which nodes in the DOM, and attaches style to them as required (this intermediate step is called a render tree).
- The render tree is laid out in the structure it should appear in after the rules have been applied to it.
- The visual display of the page is shown on the screen (this stage is called painting).
The following diagram also offers a simple view of the process.
The DOM and CSSOM:
A DOM has a tree-like structure. Each element, attribute, and piece of text in the markup language becomes a DOM node in the tree structure. The nodes are defined by their relationship to other DOM nodes. Some elements are parents of child nodes, and child nodes have siblings. The browser undergo a process that includes conversion, tokenization, lexing, and parsing which ultimately constructs the DOM and CSSOM.
- Conversion: Reading raw bytes of HTML and CSS off the disk or network.
- Tokenization: Breaking input into chunks (ex: start tags, end tags, attribute names, attribute values), striping irrelevant characters such as whitespace and line breaks.
- Lexing: Like the tokenizer, but it also identifies the type of each token (this token is a number, that token is a string literal, this other token is an equality operator).
- Parsing: Takes the stream of tokens from the lexer, interprets the tokens using a specific grammar, and turns it into an abstract syntax tree.
Example: DOM Representation
<p>
Let's use:
<span>Cascading</span>
<span>Style</span>
<span>Sheets</span>
</p>
In the DOM, the node corresponding to our <p> element is a parent. Its children are a text node and the three nodes corresponding to our <span> elements. The SPAN nodes are also parents, with text nodes as their children:
P
├─ "Let's use:"
├─ SPAN
| └─ "Cascading"
├─ SPAN
| └─ "Style"
└─ SPAN
└─ "Sheets"
Applying CSS to the DOM
span {
border: 1px solid black;
background-color: lime;
}
Once both tree structures are created, the rendering engine then attaches the data structures into what's called a render tree as part of the layout process. The render tree is a visual representation of the document which enable painting the contents of the page in their correct order.
Render tree construction follows the following order:
- Starting at the root of the DOM tree, traverse each visible node.
- Omit non visible nodes.
- For each visible node find the appropriate matching CSSOM rules and apply them.
- Emit visible nodes with content and their computed styles.
- Finally, output a render tree that contains both the content and style information of all visible content on the screen.